Overview
Learning performant robot manipulation policies can be challenging due to high-dimensional continuous actions and complex physics-based dynamics. This can be alleviated through intelligent choice of action space. Operational Space Control (OSC) has been used as an effective task-space controller for manipulation. Nonetheless, its strength depends on the underlying modeling fidelity, and is prone to failure when there are modeling errors. In this work, we propose OSC for Adaptation and Robustness (OSCAR), a data-driven variant of OSC that compensates for modeling errors by inferring relevant dynamics parameters from online trajectories. OSCAR decomposes dynamics learning into task-agnostic and task-specific phases, decoupling the dynamics dependencies of the robot and the extrinsics due to its environment. This structure enables robust zero-shot performance under out-of-distribution and rapid adaptation to significant domain shifts through additional finetuning. We evaluate our method on a variety of simulated manipulation problems, and find substantial improvements over an array of controller baselines.
Algorithm
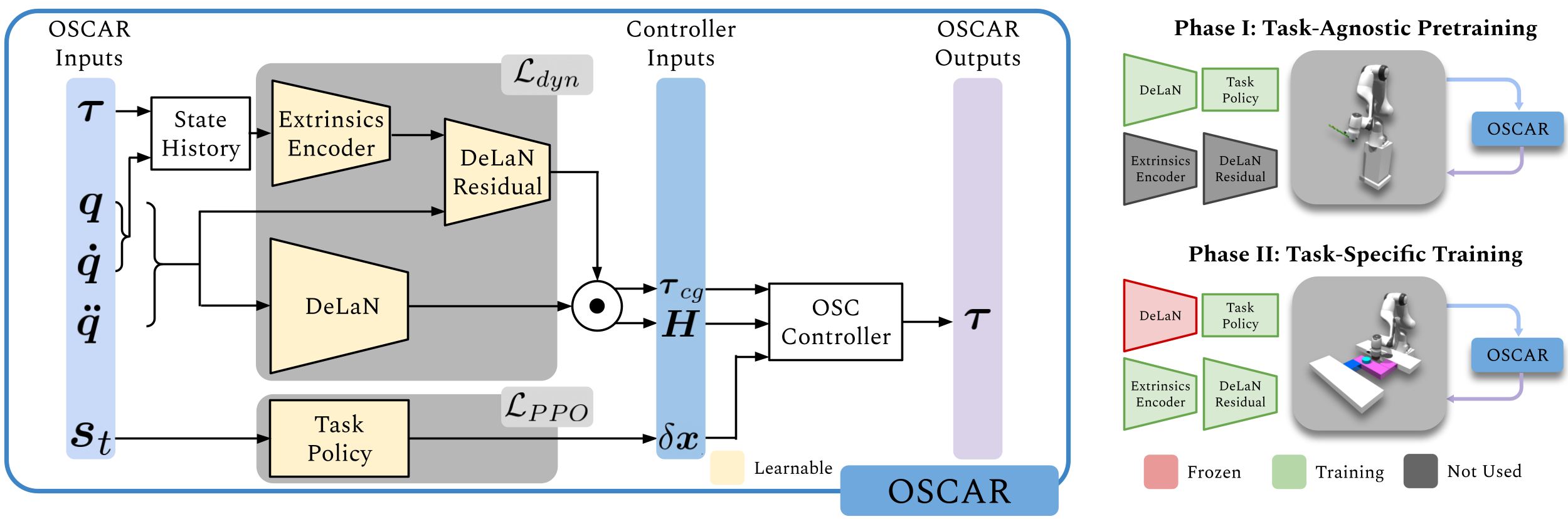
OSCAR learns a dynamics model in two-steps:
-
Task-Agnostic Pretraining: An initial reference model is learned, using free-space trajectories with no end-effector weight or dynamics randomization. This decouples the effect of task-specific dynamics from robot-specific dynamics.
-
Task-Specific Finetuning: Our dynamics model is finetuned via a residual network that perturbs the original base prediction. This residual receives recent state-action history and can infer task-relevant dynamics. We learn this dynamics model simultaneously with a task policy.
Performance
Team
 Josiah Wong
Josiah Wong
 Viktor Makoviychuk
Viktor Makoviychuk
 Anima Anandkumar
Anima Anandkumar
 Yuke Zhu
Yuke Zhu
Citation
@inproceedings{wong2022oscar,
title={OSCAR: Data-Driven Operational Space Control for Adaptive and Robust Robot Manipulation},
author={Josiah Wong and Viktor Makoviychuk and Anima Anandkumar and Yuke Zhu},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2022}
}